ETL
Da questa scheda, sezione Sequenza ETL, sarà possibile personalizzare i passi dei vari Job.
Al momento l’unica personalizzazione possibile è l’aggiunta del passo di REPLICA di MEXAL DB.
In questo modo, lanciando il job predefinito così salvato (da Job – Etl – Caricamento) verranno popolate le tabelle del database di Mexal DB e successivamente partità l’etl sul database del datawarehouse di PAN:
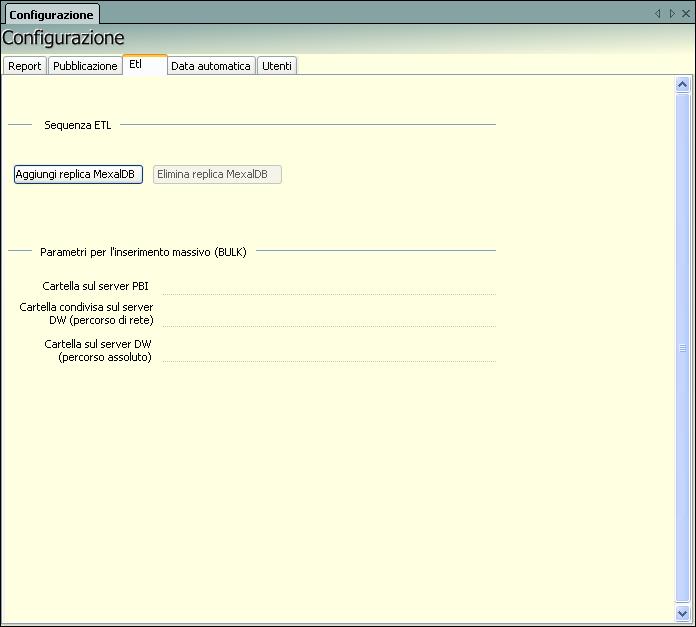
Aggiungi replica Mexal DB – questo tasto aggiunge due passi alla sequenza ETL : la Replica Mexal DB e il Tronca Replica DB (questo secondo passo sarà incluso nella sequenza solo se si dispone di un’installazione di Mexal DB per PAN):

Dopo aver lanciato un successivo etl, come si può vedere dall’immagine di cui sopra, tra i passi della sequenza ETL compariranno anche i passi 1 e 22 ossia quelli aggiunti tramite il pulsante “Aggiungi replica Mexal DB”.
Elimina replica Mexal DB – questo tasto elimina i due passi : Replica DB e Tronca replica Mexal DB dalla sequenza ETL.
La procedura di replica automatica, da PAN, delle tabelle del database fonte di Mexal è obbligatoria solo per installazioni di PAN (dalla versione 2.4 in avanti) con Mexal DB per PAN.
All’interno di questa scheda sono contenuti, inoltre, nella sezione: Parametri per l’inserimento massivo, i parametri di default relativi alla scelta dell’etl con modalità bulk.

Cartella sul server PAN: deve essere indicato un percorso locale sul server PAN nel quale saranno salvati temporaneamente i file dell’etl. Es: c:\etl.
Condivisa sul server DW : deve essere indicato il path di rete della cartella nel Server DB dove salvare temporaneamente i file bulk. Es: \\serverdb\condivisa (per windows e linux uguale, perchè la condivisione è fatta con Samba).
Cartella sul server DW : deve essere indicato il path locale della cartella nel DB Server dove salvare temporaneamente i file bulk . Es: per windows C:\database\PAN, per linux: /database/PAN.
Con questa modalità sarà eseguito l'etl appoggiando temporaneamente i dati su file ed eseguendo in seguito l'inserimento massivo (bulk insert) nel Data Warehouse.
In questo modo l’etl sarà più veloce; la scelta è infatti da preferire per grosse moli di dati.
I percorsi indicati da questa scheda saranno visualizzati dalla finestra Etl - Caricamento dalla quale si potrà scegliere se lanciare l’etl con questa modalità.